Przetwarzanie i dystrybucja danych
W przypadku rozpoczęcia procesu przetwarzania danych analizując przedstawiony na Rys. 13 można wydzielić następujący schemat przepływu - Rys. 27:

Rys. 27. Schemat przepływu sterowania w procesie przetwarzania
Do przeprowadzania procesu przetwarzania potrzebne będzie przygotowanie danych i zbudowanie ciągu przetwarzającego dane. W ramach tego ciągu na wejściu użyjemy przygotowanego pliku z planem realizacji zapytania, przygotujemy plik binarny z danymi. Zbudujemy proces przetwarzający dane i prezentujący wyniki.
Źródłowy plik danych query.rql zmienimy na następujący:
DECLARE a INTEGER \
STREAM core0, 0.1 \
FILE 'datafile1.txt'
DECLARE a BYTE \
STREAM core1, 0.2 \
FILE '/dev/urandom'
SELECT str1[0], str1[0] + str1[1]/20 \
STREAM str1 \
FROM core0 + core1
W tym przykładzie deklarujemy istnienie pliku tekstowego zawierającego dane tekstowe. Proponuję wypełnić plik datafile1.txt następującą zawartością:
$ seq 20 28 > datafile1.txt
20
21
22
23
24
25
26
27
28
Plik będzie zawierać kolejne liczby od 20 do 28.
Rzut okna na plan realizacji zapytania przedstawi obraz na Rys. 28:
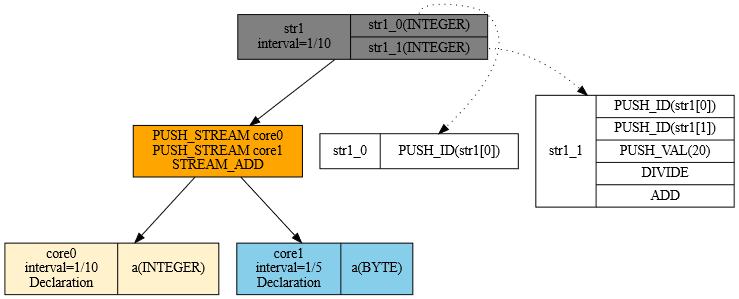
Rys. 28. Graficzna reprezentacja planu realizacji zapytania 2
Jeśli przygotowaliśmy plik z danymi możemy uruchomić proces kompilacji i przetwarzania danych. Realizujemy to wydając następujące polecenie:
$ xretractor query.rql
I tu pojawia się istotna właściwość opracowanego systemu. System powinien rozpocząć natychmiast realizację procesu. Dowolny klawisz naciśnięty w terminalu przerwie ten proces.
Proponuję uruchomić drugie okno terminala i tam kontynuować sesję. W drugim oknie terminala możemy wydać następujące polecenie:
$ xqry -d
| str1|1/10|6912|864| |0|
|core0|1/10| -1| 49|datafile1.txt|1|
|core1| 1/5| -1| 25| /dev/urandom|1|
Powinno się pojawić coś podobnego. Oczywiście liczniki danych przy str1 powinny się różnić. Logicznym jest że za każdym odczytem otrzymamy większe wartości dotyczące rozmiaru zgromadzonego strumienia str1.
Jeśli chcemy na ekranie zobaczyć co tam się właśnie dzieje wewnątrz procesu przetwarzania danych proponuję wydać poniższe polecenie i po kilku wierszach na ekranie nacisnąć dowolny klawisz aby przerwać ten proces:
$ xqry -s str1
20 26
21 33
22 34
23 27
24 28
25 35
26 36
27 28
Pierwsza kolumna zawiera sekwencję liczb – taką jaką wpisaliśmy do pliku datafile1.txt. Druga kolumna zawiera efekt przetwarzania. Dodawana jest wartość pobrana z generatora liczb pseudolosowych podzielona przez 20 – druga kolumna opływa dane poniżej kolumny pierwszej.
Jak można to zobaczyć w formie graficznej? Proponuję wydać następujące polecenie:
$ xqry -s str1 -p 50,50 | gnuplot
Na ekranie pojawi się następujące okno z płynącymi na bieżąco danymi:
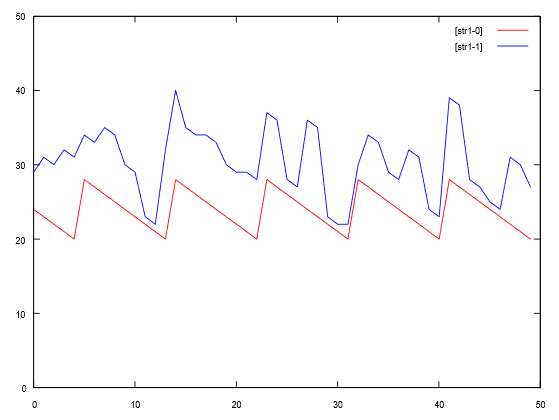
Rys. 29. Zrzut zawartości okna gnuplot przedstawiający dane napływające
Na Rys. 29 widzimy to co dane przedstawiały w postaci numerycznej. Kształt piły to pierwsza kolumna, nieregularny kształt opływający kształt piły to druga kolumna. Rysunek przedstawia dane statyczne – w oknie jednak dane te napływają i rysunek jest aktualizowany na bieżąco.
Typowym pomysłem na wysłanie danych poza system na którym funkcjonuje xretractor i xqry jest użycie polecenia:
$ xqry -s str1 | nc -l 8888
na drugim komputerze trzeba napisać:
$ nc nazwa_serwera_lub_jego_ip 8888
ℹ️ Info
Flaga
-pw netcat (składnia BSD) nie jest obsługiwana przez GNU netcat dostępny na współczesnych systemach Ubuntu/Debian. Poprawna składnia tonc -l 8888(bez-p).
Transmisja danych odbędzie się przez sieć.
Jeśli chcemy zakończyć proces xretractor za pomocą polecenia xqry możemy wydać następujące polecenie:
$ xqry -k
kill sent to server
ok.
Po wydaniu tego polecenia proces xretractor zakończy swoje działanie i przerwie przetwarzane planów realizacji zapytań.
Zapis procesu prezentowany na ekranie (Rys. 30) przedstawia się następująco:
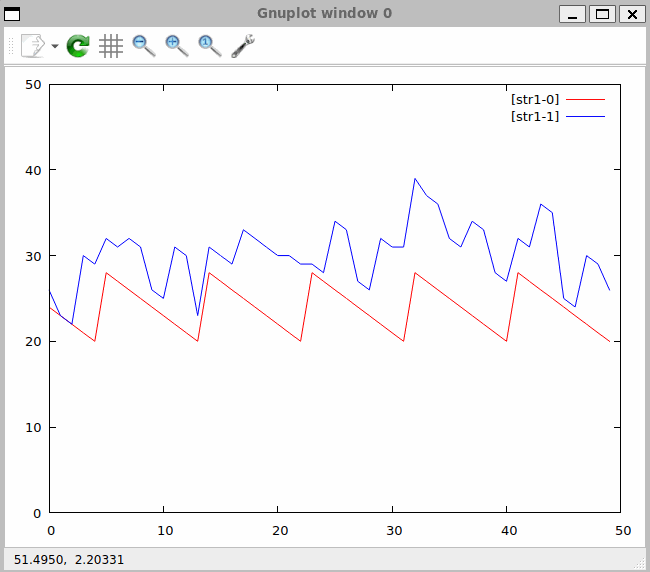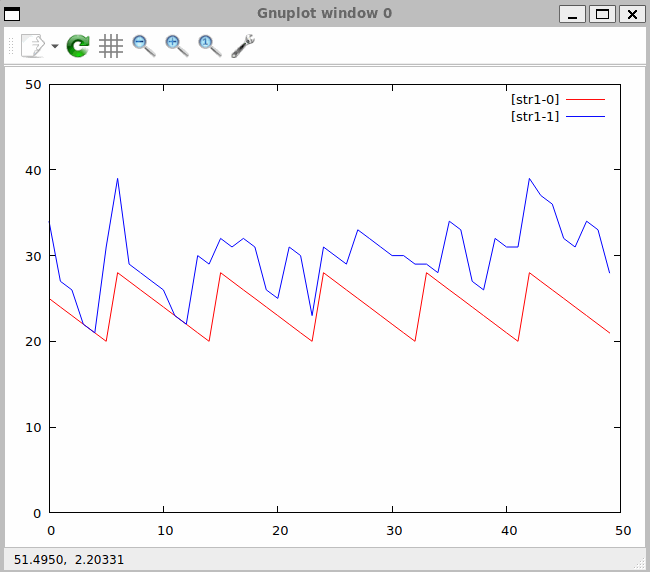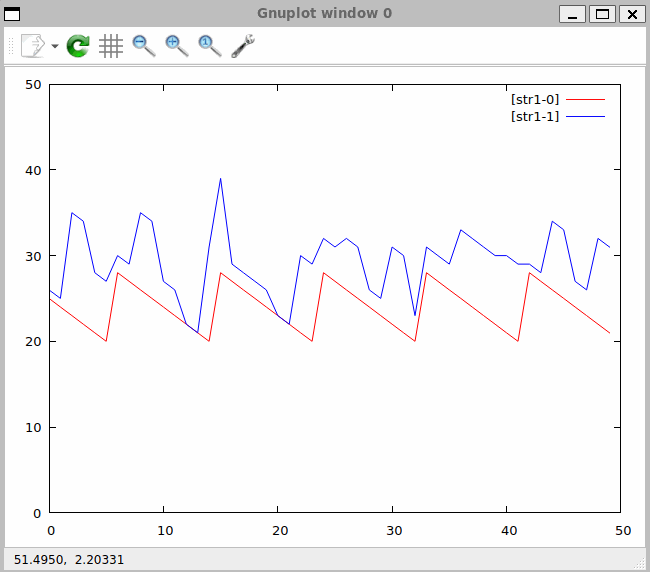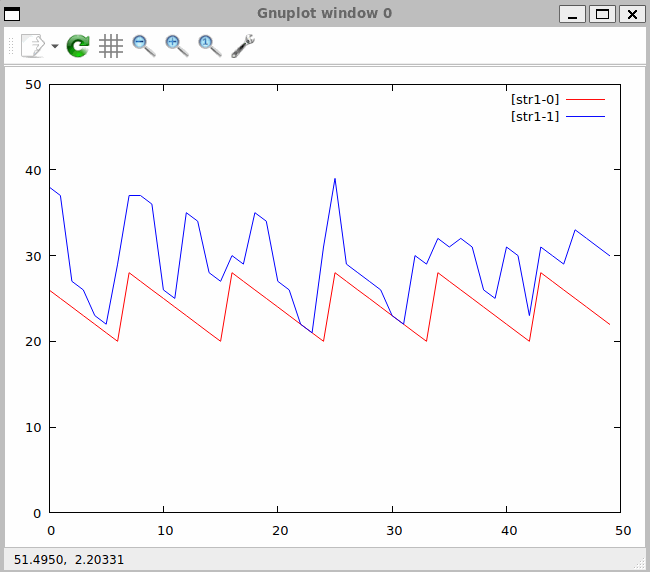
Rys. 30. Zapis procesu przetwarzania danych w czasie rzeczywistym